neural networks with MATLAB’S fitcnet & Python’s TensorFlow for a consistent assay-specific classifier.
unform manifold approximation and projection (umap)
produces a lower-dimensional representation of the data for data visualization and exploration
EXHAUSTIVE PROJECTION PURSUIT (epp)
designed to find subsets based on phenotyping markers and scatter parameters
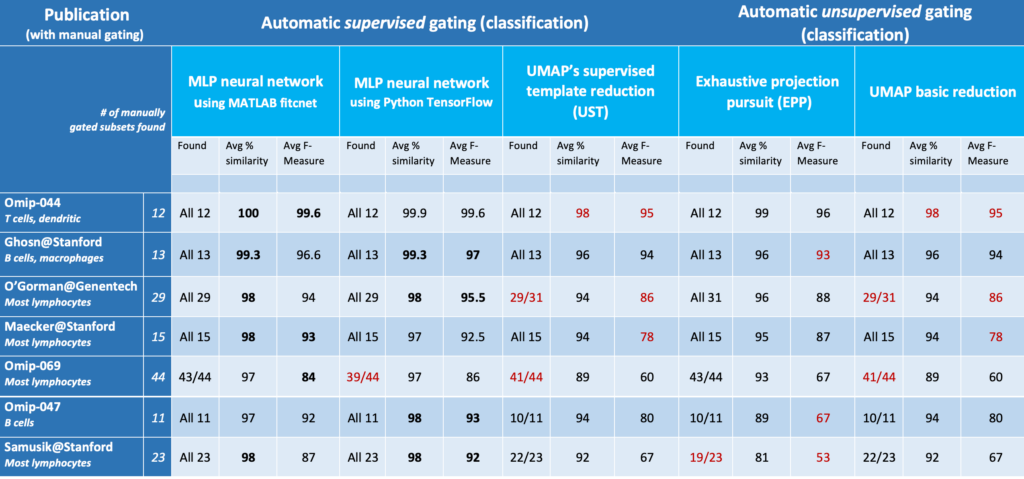
RESULTS with AUTOMATED METHODS
COMPARISON OF AUTOMATED METHODS
AutoGate in the last 3 years has acquired 5 fully automatic gating methods. Two methods are unsupervised: Exhaustive Projection Pursuit (EPP) and Uniform Manifold Approximation and Projection (UMAP). Three methods are supervised: multilayer perceptron (MLP) neural network based on MATLAB fitcnet; MLP based on Python TensorFlow and UMAP supervised templates.